Anastasia Kuznetsova
PhD Candidate in Computer Science and Computational Linguistics
Indiana University Bloomington
PhD Candidate in Computer Science and Computational Linguistics
Indiana University Bloomington
Discrete audio and semantic tokens inspired by large language models gained popularity not only in natural language processing but also in speech and audio applications. The potential of neural codecs and semantic SSL representations has been vastly explored for reducing the training complexity of a variety of the downstream tasks. However, for the transmission and communication scenarios, when the ASR system is deployed on the edge devices, the bitrate of the speech tokens is of the utmost importance. In this project, we explore the lower bound of the bitrate of the discrete representations for ASR systems without loss of the recognition accuracy. To save the space on device and reduce the transmission latency, we propose quantization method for the ASR encoder.
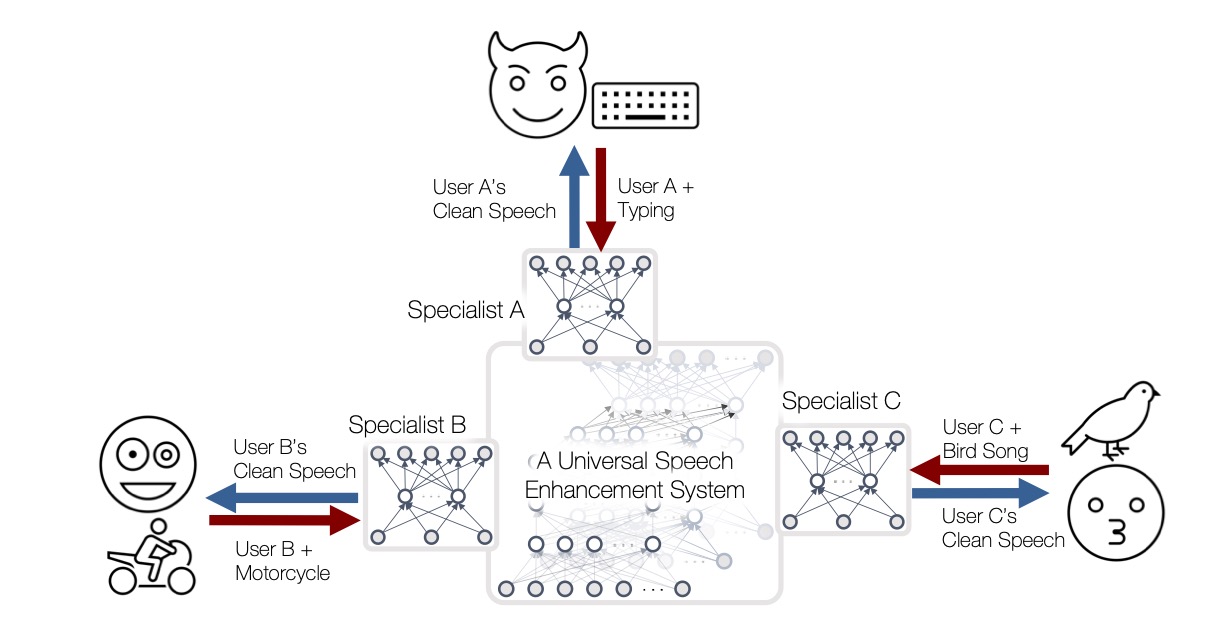
With the advances in deep learning, speech enhancement systems benefited from large neural network architectures and achieved stateof-the-art quality. However, speaker-agnostic methods are not always desirable, both in terms of quality and their complexity, when they are to be used in a resource-constrained environment. One promising way is personalized speech enhancement (PSE), which is a smaller and easier speech enhancement problem for small models to solve, because it focuses on a particular test-time user. To achieve the personalization goal, while dealing with the typical lack of personal data, we investigate the effect of data augmentation based on neural speech synthesis (NSS). In the proposed method, we show that the quality of the NSS system’s synthetic data matters, and if they are good enough the augmented dataset can be used to improve the PSE system that outperforms the speaker-agnostic baseline. The proposed PSE systems show significant complexity reduction while preserving the enhancement quality.
End-to-end speech recognition models show astonishing results in transcribing audio signals into written text. However, conventional data feeding pipelines may be suboptimal for low-resource speech recognition, which still remains a challenging task. We propose an automated curriculum learning approach to optimize the sequence of training examples based on both the progress of the model while training and prior knowledge about the difficulty of the training examples. We introduce a new difficulty measure called compression ratio that can be used as a scoring function for raw audio in various noise conditions. The proposed method improves speech recognition Word Error Rate performance by up to 33% relative over the baseline system.
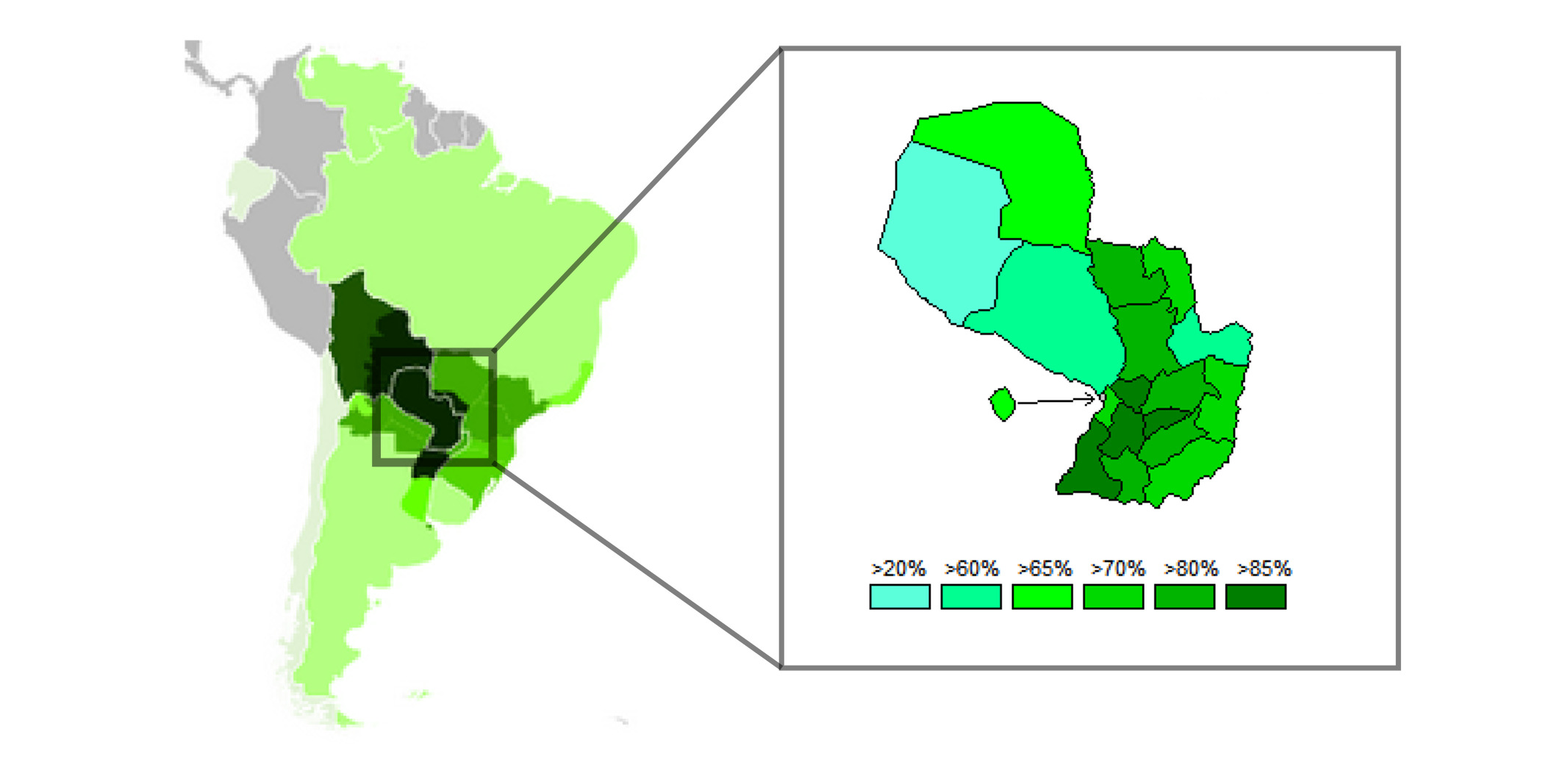
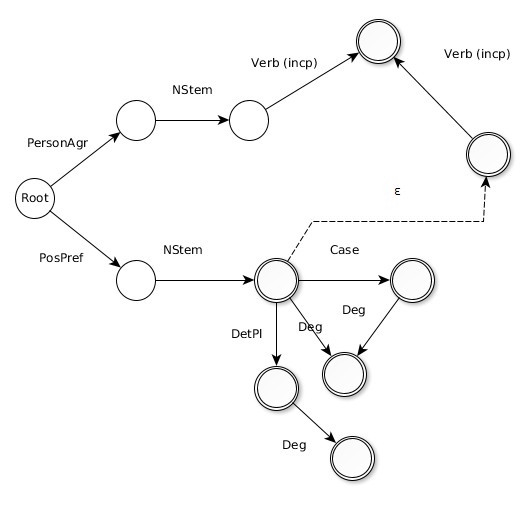
This project involves developing a finite-state morphological analyser for Paraguayan Guaraní, an indigenous language spoken in Paraguay. The analyser uses finite-state transducers to model the morphological processes of the language, enabling accurate analysis and generation of word forms.
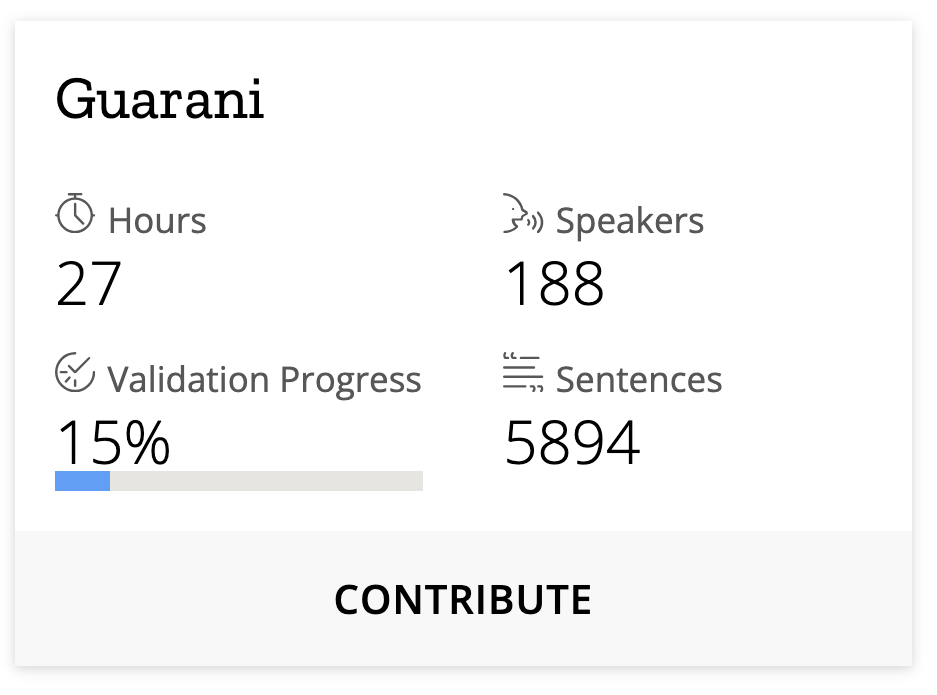
In partnership with Mozilla, Aperitum and Academía de la Lengua Guaraní (Paraguay) collected audio and text for the open sourced Common Voice dataset. The dataset was officially released and currently contains 27 hours of spoken speech, 188 speakers and 5894 sentences.